Or just keep database and application co-located :)
It is well-known from the get-go, but very often overlooked because of ignorance or laziness: the database application must be co-located with the database server. Row-by-row roundtrips between the application and the database are expensive. Not only due to the network latency, but also because of the many CPU cycles wasted to switch the context between the two engines, or the two processes, and maybe the two servers.
In modern architectures, with microservices and containers, this means that a business service must be implemented in one microservice containing the business logic and the business data. Separating the application and the database into two microservices is a wrong design, non-efficient, non-scalable, and also non-green because of the unnecessary CPU usage.
Docker
I was building a new demo for this, as in the previous post, where I compare running the procedural code in the client or the server side of the database. When I was running my database in a Docker container, I’ve seen that the bad performance I wanted to show was even worse than expected:
- the symptom was high CPU usage in “docker-proxy” process
- the cause was that I’m using the default Docker userland proxy
Here is the related Twitter thread. Thanks to @G_Ceresa, @ochoa_marcelo, and @ofirm for the quick replies about the cause and solution:
😭My demo on roundtrips between client and server takes 2x longer when the DB runs on Docker 😲Most of the CPU time wasted in docker-proxy (paravirtualisation spin lock slow path?) 🤔This @Docker thing is a bad joke 😡wasting my time with software delivered as docker image only
This post is a replay of the issue, with PostgreSQL as the database and PgBench as the client application. There’s a summary at the end, but I like to show all the steps.
Setup with PostgreSQL
I got the issue with an Oracle database, but I reproduced it with PostgreSQL. I start with a default docker 18.09 installation on CentOS 7.6 and 4 cores.
yum -y install docker-ce
systemctl start docker
I have the following docker-compose to get a client and server container:
version: '3.1'
services:
server:
image: postgres:latest
restart: always
environment:
POSTGRES_PASSWORD: demo
POSTGRES_DB: postgres
POSTGRES_INITDB_ARGS:
POSTGRES_INITDB_WALDIR:
PGDATA: /var/lib/postgresql/data
ports:
- 5432:5432
client:
image: postgres:latest
restart: always
environment:
PGPASSWORD: demo
links:
- server
In addition to that, as I want to run the clinet (pgbench) from outside, I’ve installed it on the host:
yum install -y postgresql-contrib
I create the containers and initialize PgBench with a small database so that everything is in memory as I don’t want I/O latency there:
docker-compose -f crosscontainerpgbench up -d --remove-orphans
docker exec -i crosscontainerpgbench_server_1 psql -U postgres -e <<'SQL'
drop database if exists demo;
create database demo;
SQL
docker exec -i crossconainerpgbench_server_1 pgbench -i -s 5 -U postgres demo
Test with pgbench — default Docker configuration
I’ll simply run a select-only (I don’t want disk I/O in order to have predictable results) workload with 5 clients:
pgbench -c 5 -j 1 -t 100000 -S -M prepared
I’ll run that from:
- the DB server container, as if all is embedded in the same service
- the client container, as if I have two containers for DB and application
- the host, like when the application is running outside of the docker server
I’ll compare the transactions per second, and have a look at the CPU usage.
Application in the same container
Here is the run from the database server container:
+ docker exec -i crosscontainerpgbench_server_1 pgbench -c 5 -j 1 -t 100000 -S -M prepared -h localhost -U postgres demo
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
latency average = 0.286 ms
tps = 17510.332823 (including connections establishing)
tps = 17512.433838 (excluding connections establishing)

Application in another container
Here is the run from the client container through a network link to the server one:
+ docker exec -i crossconainerpgbench_client_1 pgbench -c 5 -j 1 -t 100000 -S -M prepared -h server -U postgres demo
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
latency average = 0.358 ms
tps = 13964.823706 (including connections establishing)
tps = 13966.547260 (excluding connections establishing)
This is a lower transaction per second rate when not running from the same container.

Application outside of any container
Here is the run from the host where the 5432 port is exposed:
+ pgbench -c 5 -j 1 -t 100000 -S -M prepared -h localhost -U postgres demo
starting vacuum...end.
transaction type: SELECT only
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
tps = 10803.986896 (including connections establishing)
tps = 10810.876728 (excluding connections establishing)
this is very bad performance when compared to the previous ones. Here is what TOP is sowing during the execution:

This docker-proxy is a userland proxy implemented by Docker. It is obviously not efficient given the amount of CPU resource required to just copy the network messages between processes.
Test with pgbench —without the Docker proxy
Now, thanks to the replies to my tweet, I got this default (legacy) behavior explained. Docker runs this process as a workaround for old bugs, but we can disable it.
I’ve added the following in /etc/docker/daemon.json and restarted docker:
{
"userland-proxy": false
}Now, the port redirection is ensured by iptables only:
# iptables -t nat -L -n -v | grep NAT
0 0 DNAT tcp -- !br-86c9e5013bd1 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:5432 to:172.21.0.2:5432
Yes, as scary as it sounds, docker can manipulate your iptables without asking you. Remember that you run it as root… so be careful.
Now, same tests as before…
Application in the same container
From the database server container itself:
+ docker exec -i crossconainerpgbench_server_1 pgbench -c 5 -j 1 -t 100000 -S -M prepared -h localhost -U postgres demo
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
latency average = 0.274 ms
tps = 18218.661669 (including connections establishing)
tps = 18220.944898 (excluding connections establishing)
Application in another container
From the client container:
+ docker exec -i crossconainerpgbench_client_1 pgbench -c 5 -j 1 -t 100000 -S -M prepared -h server -U postgres demo
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
latency average = 0.323 ms
tps = 15497.325700 (including connections establishing)
tps = 15499.077232 (excluding connections establishing)
Application outside of any container
From the host, without the userland proxy. Note that I use the IPv4 address for localhost here because where connecting to localhost iptable was dropping the packets:
+ pgbench -c 5 -j 1 -t 100000 -S -M prepared -h 127.0.0.1 -U postgres demo
starting vacuum...end.
transaction type: SELECT only
scaling factor: 5
query mode: prepared
number of clients: 5
number of threads: 1
number of transactions per client: 100000
number of transactions actually processed: 500000/500000
tps = 16540.617239 (including connections establishing)
tps = 16552.098558 (excluding connections establishing)
This is correct, even better than when running from another container, but of course lower than when running in the same container.
In summary…
There’s a huge difference when this ‘docker-proxy’ is not running in the middle. Now, all pgbench runs are in the same ballpark, within 10%.
I have run the same tests in a loop in order to get an average. First, here is the standard deviation that I prefer to check because I’m not familiar enough with pgbench (and docker) performance predictability:

And here the results showing the average transactions-per-second with both settings for the docker proxy, and with different colocation of pgbench and DB server: on the docker host in blue, in a different docker container in orange, within the same container in green:
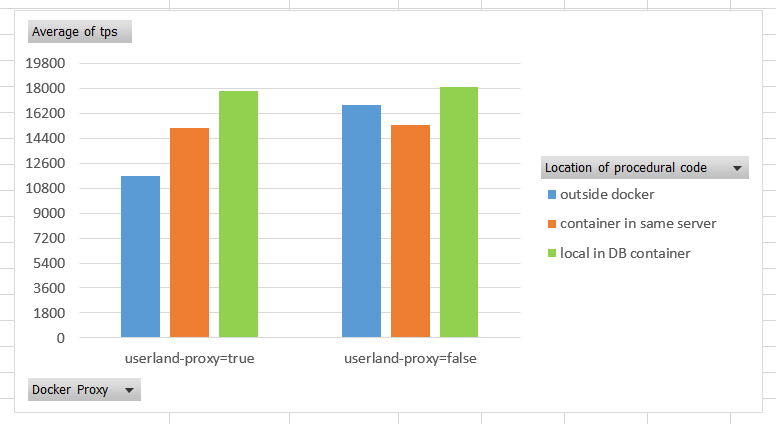
It looks like keeping the default value for ‘userland-proxy’ is never good. It forces all external network communication to go through this inefficient process. The performance here slows down to 40% when connecting from outside.
The most important is that even with the ‘userland proxy’ disabled, we see a 10% degradation when not running the application in the same container as the database. There’s no magic: the more physical layers you add, the worst performance you get. It can be a small overhead (when the layer is an optimal virtualization) or a huge waste of CPU cycles. Microservices and logical layers are good for the development organization. But when it comes to the platform dependent implementation, colocation is the key to scalability. Build small services, but run them colocated: either the database is embedded in the container, or the procedural code is executed in the database.
I’m talking about this at Riga Dev Days — “Microservices: Get Rid of Your DBA and Send the DB into Burnout”:
Feel free to comment on Twitter https://twitter.com/franckpachot



















































