TL;DR: AUTOCOMMIT is required when calling a procedure which has some COMMIT inside.
In version 11 PostgreSQL has introduced the possibility to start, commit or rollback transactions in PL/pgSQL procedures (stored or anonymous). Most of the demos have been run from the psql default AUTOCOMMIT on, like 2ndQuadrant and dbi-services blogs. But Bryn Llewellyn (YugaByte) raised an issue when running without AUTOCOMMIT OFF (which, coming from Oracle, looks like the right choice). Here is my investigation on this.
You should read my last post Transaction management in PostgreSQL and what is different from Oracle if you are not totally familiar with PostgreSQL transaction management and auto-commit, as I wrote it as an introduction to this analysis.
Tracing with GDB
Here is what I run (I’m using the function from the previous post):
psql
\set PROMPT1 '\t\t\t\t\t\t>>>%`date +%H:%M:%S`<<<\n%/%R%# '
select pg_backend_pid();
-- attach gdb to backend and set breakpoint on exec_simple_query
\echo :AUTOCOMMIT
call my_inserts(1111,1111);
-- gdb stops on breakpoint and continue
\set AUTOCOMMIT off
call my_inserts(1112,1112);
-- gdb stops on breakpoint and continue
Here is my gdb session on a second terminal:
gdb -p $(pgrep -nl postgres)
define hook-stop
shell echo -e "\t\t\t\t\t\t>>>`date +%H:%M:%S`<<<"
end
print getpid()
break exec_simple_query
cont
## back to psql to call the procedure
print query
cont
## back to plsql to set AUTOCOMMIT off and run again
I have added timestamps in both prompts in order to show the sequence in one screenshot. Here is the result. The first call succeeded (in AUTOCOMMIT on) but the second call failed (with AUTOCOMMIT off) because psql has issued a BEGIN before the CALL:
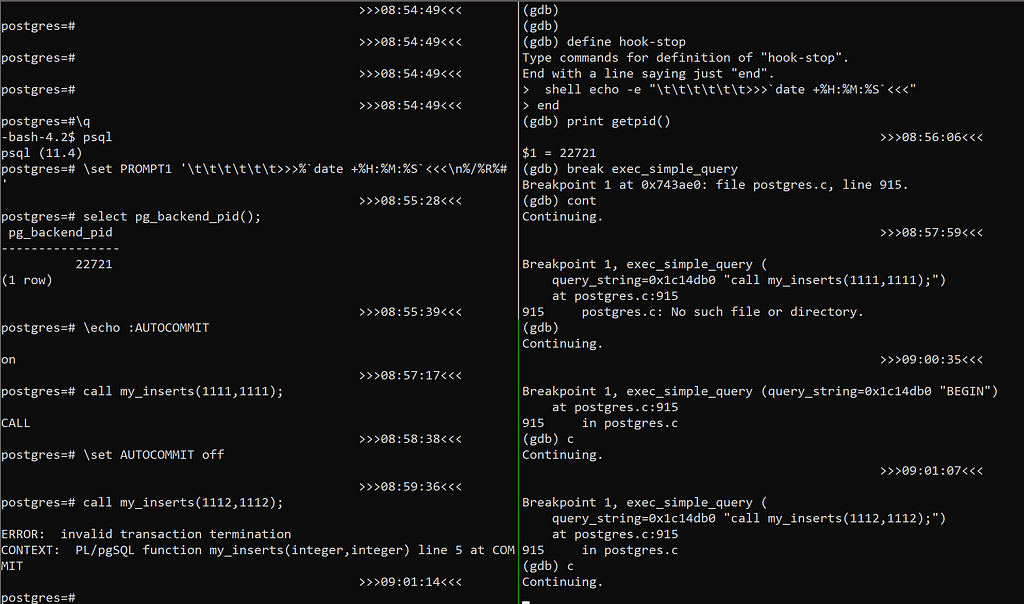
I have 2 questions here:
- Why does psql initiates a transaction before the call when it is not in AUTOCOMMIT?
- Why does the procedure’s COMMIT fail when in a transaction opened outside of the procedure?
Why does the COMMIT fail when in a transaction opened outside?
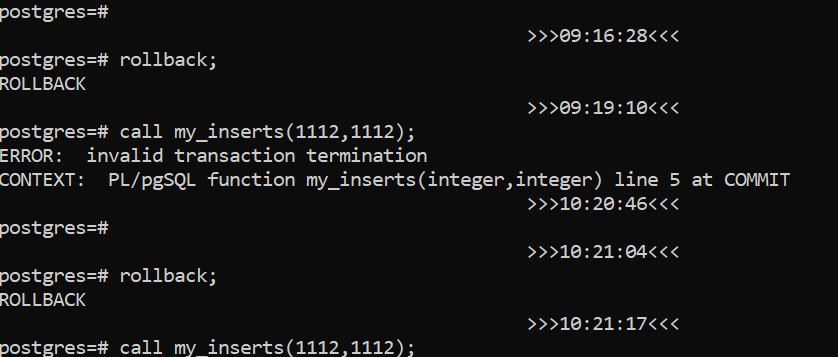
From the previous step, I rollback (the transaction, initiated by the client when in AUTOCOMIT off, was aborted). And call the procedure again after having set the following breakpoints:
break SPI_start_transaction
break SPI_commit
print _SPI_current->atomic
cont
I’ve set those and displayed “atomic” because the error message comes from the following PostgreSQL code:

set pagination off
print _SPI_current->atomic
backtrace
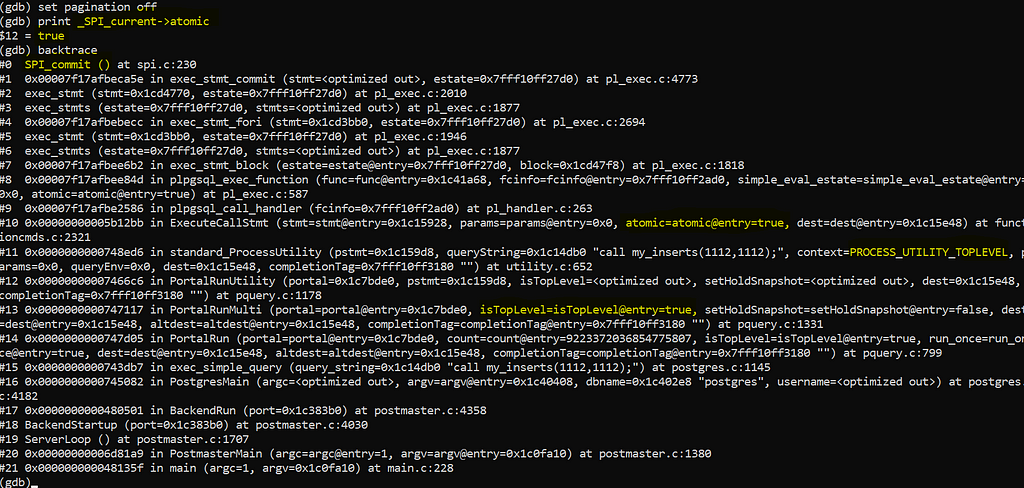
I can see atomic=true in the call to the following function
ExecuteCallStmt(CallStmt *stmt, ParamListInfo params, bool atomic, DestReceiver *dest)
and the comments in functioncmds.c explains the idea of “atomic commands” — those were transaction control commands are disallowed. Here is the postgres source code and the explanation:
* Inside a top-level CALL statement, transaction-terminating commands such as COMMIT or a PL-specific equivalent are allowed. The terminology in the SQL standard is that CALL establishes a non-atomic execution context. Most other commands establish an atomic execution context, in which transaction control actions are not allowed.
This makes sense. But I am in a “top-level CALL statement”, so why is atomic set to true? The parent in the stack is standard_ProcessUtility and here is how atomic is defined:
bool isAtomicContext = (!(context == PROCESS_UTILITY_TOPLEVEL || context == PROCESS_UTILITY_QUERY_NONATOMIC) || IsTransactionBlock());
Ok, I think I got it. There’s another reason to set atomic=true: I am in already in a transaction block. Just confirmed by running the same
with those additional breakpoints:
break standard_ProcessUtility
continue
print context
print IsTransactionBlock()
continue
print context
print IsTransactionBlock()
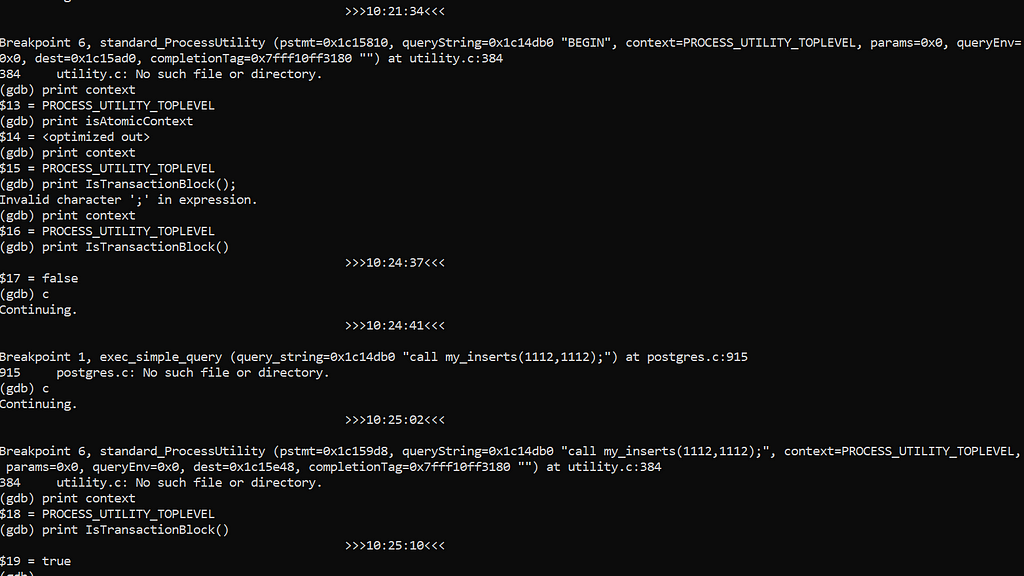
So, I am already in a transaction when executing the CALL and documentation says that:
If CALL is executed in a transaction block, then the called procedure cannot execute transaction control statements
Ok, documentation is perfect. Why did I need to gdb in order to get this? It’s more fun 🤓 and probably the error message is really bad. A generic “invalid transaction termination” because the only info that was passed is that we are in an atomic command. The error message should mention that we are either in a transaction block or in a recursive call.
While here, I’ll mention a pgsql-hackers thread about another reason why we can get the same error, because an atomic context is forced by query snapshot management: “SPI Interface to Call Procedure with Transaction Control Statements?”.
Anyway, I agree that I should not start a transaction in the client and commit it in the procedure. Transaction control should stay on the same layer. But… I never wanted to start a transaction from the client and this brings me to the second question:
Why does psql initiate a transaction before CALL?
While my psql client is still hanging (because of the breakpoint stop on the backend), on another terminal I attach gdb to it:
gdb -p $(pgrep -nl psql)
define hook-stop
shell echo -e "\t\t\t\t\t\t>>>`date +%H:%M:%S`<<<"
end
print getpid()
set pagination off
backtrace
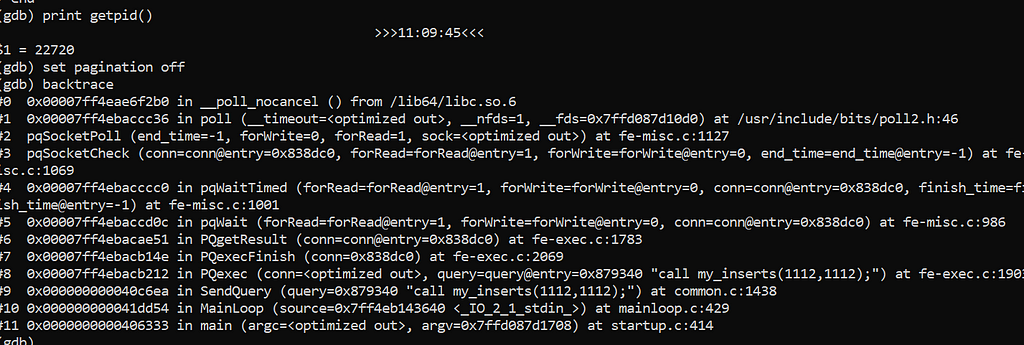
I have seen that when AUTOCOMMIT is off the backend receives a BEGIN command. This can be found in SendQuery from common.c is:
transaction_status = PQtransactionStatus(pset.db);
if (transaction_status == PQTRANS_IDLE &&
!pset.autocommit &&
!command_no_begin(query))
{
results = PQexec(pset.db, "BEGIN");
So, basically, if there’s no transaction and we are not in AUTOCOMMIT, plsql will execute a BEGIN before the command except if the command itself is a command that starts the transaction.
Here, I’m attached when the CALL command is sent and I’m already in an active transaction:
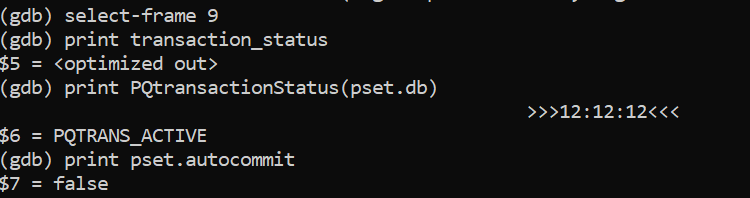
but when there’s no transaction already (PQTRANS_IDLE), then psql executes a BEGIN command, except when command_no_begin returns true. And CALL is not one of those.
Is that a psql bug or expected feature? Let’s see what happens with JDBC
What about JDBC?
JDBC drivers also have the AUTOCOMMIT set by default. I run the following:
import java.io.*;
import java.sql.*;
import java.util.*;
import java.time.*;
import oracle.jdbc.*;
public class JDBC {
public static void println(String text){
System.out.println(Instant.now().toString() +":" + text);
}
public static void main(String[] args)
throws SQLException,InterruptedException {
try (Connection c = (Connection) DriverManager.getConnection(
args[2],args[0],args[1]) // url, user, password
) {
println(" AUTOCOMMIT: "+c.getAutoCommit());
try (CallableStatement s=c.prepareCall("call my_inserts(2,3)")){
s.execute();
}
println(" DONE. ");
c.setAutoCommit(false);
println(" AUTOCOMMIT: "+c.getAutoCommit());
try (CallableStatement s=c.prepareCall("call my_inserts(4,5)")){
s.execute();
}
println(" DONE. ");
}and here is the result of this code:

Same behavior with JDBC: the first call, with AUTOCOMMIT, succeded but then the second call, where AUTOCOMMIT is disabled, failed.
So… is that a constant behavior among all PostgreSQL clients? Let’s try Python.
What about psycopg2?
I quickly checked from a Jupyter Notebook I had from a previous blog post (iPython-SQL/SQLAlchemy/psycopg2)
Here, the transaction management in the procedure works in both cases, whatever the AUTOCOMMIT setting is. However, are we sure that I am not in auto-commit? I’ve added an additional insert after my commit in the procedure. And it seems that all was committed at the end of the call…
So what?
I started this investigation (which I didn’t expect to be so long) after Bryn Llewellyn raised the following issue at YugaByte (the SQL API of YugaByteDB, YSQL, is based and compatible with PostgreSQL):
Having transaction control in PostgreSQL is a nice feature that appeared recently (PostgreSQL 11) and for the moment it seems that there are some inconsistencies between the clients. In its current state, it is designed for AUTOCOMMIT, so that the procedure itself starts and ends the transaction from the backend.
Don’t hesitate to comment and give feedback, preferably on Twitter:
🤔Any @planetpostgres followers having an idea why transaction control is refused in procedures except when client is in AUTOCOMMIT mode❓ (non autocommit -> "invalid transaction termination") 😕Comments are very sparse in spi.c https://t.co/MXxYAaFYal /cc @BrynLite































































